Document Intelligence for Australian Logistics Operations
Document intelligence uses AI to automatically extract and validate data from BOLs, PODs, freight invoices, and customs documents — eliminating manual data entry and reducing compliance risk. This guide covers how Australian logistics operators can implement it, what Australian regulatory requirements apply, and how to build an ROI case using your own operational data.

Document Intelligence for Australian Logistics Operations
Document intelligence in logistics is the use of AI to automatically extract, validate, and route structured data from unstructured documents — bills of lading, proof of delivery, invoices, and customs declarations — without manual data entry. For mid-market Australian operators still running on spreadsheets and email-based workflows, it's one of the highest-ROI entry points into AI.
If your team spends hours each week rekeying data from PDFs, chasing missing PODs, or reconciling freight invoices against TMS records, this guide is for you.
What Is Document Intelligence?
Document intelligence is a category of AI that combines optical character recognition (OCR), natural language processing (NLP), and machine learning to read, interpret, and act on document content. Unlike basic OCR, which simply converts images to text, document intelligence understands context — it knows that "consignee" on a BOL is different from "shipper", and that a date in a customs declaration has a different meaning than a date on a freight invoice.
For logistics operations, this means documents that previously required human eyes and keyboard input can be processed automatically, validated against business rules, and pushed directly into your TMS, WMS, or accounting system.
Why Australian Logistics Operators Are Prioritising This Now
Several converging pressures are making document automation a priority for Australian carriers, 3PLs, and freight forwarders:
Labour cost and availability. Manual document processing is repetitive, error-prone, and hard to staff. As wage costs increase and clerical talent becomes harder to retain, the economics of automation improve.
Customer expectations. Larger shippers increasingly require digital capabilities — real-time status updates, electronic PODs, API-based data exchange — as conditions of doing business. If you can't provide them, you lose the tender.
Regulatory complexity. Australian Border Force (ABF) customs requirements, the Biosecurity Act 2015, and chain-of-responsibility obligations under the Heavy Vehicle National Law (HVNL) all generate document obligations that must be traceable and accurate. Manual processes create compliance risk.
AASB S2 emissions reporting. From FY2026 onwards, many mid-market operators will need to report Scope 1 and Scope 2 emissions, with Scope 3 supply chain emissions following. Accurate emissions calculation depends on clean, structured data — the same data that currently lives in unstructured documents.
The Four Document Types That Matter Most
Bills of Lading (BOLs)

A bill of lading is the foundational document in freight — a contract, a receipt, and a title document combined. In Australian domestic freight, BOLs (or consignment notes) are also the primary record for chain-of-responsibility compliance.
Document intelligence applied to BOLs can:
- Extract consignor, consignee, origin, destination, weight, dimensions, and commodity codes automatically
- Cross-validate against booking data in your TMS to catch mismatches before the freight moves
- Flag missing or incomplete fields that would otherwise cause delays at the dock or on delivery
- Archive with full metadata for audit purposes
Proof of Delivery (PODs)
POD processing is where many mid-market operators feel the most pain. Paper PODs get lost, scanned PODs sit in email inboxes, and reconciling delivery confirmation against invoicing is a manual, time-consuming task.
AI-powered POD processing can:
- Extract signature, timestamp, receiver name, and any exception notes from scanned or photographed PODs
- Automatically update delivery status in your TMS
- Trigger invoicing workflows once delivery is confirmed
- Flag disputed deliveries based on extracted exception text (e.g. "damaged", "short delivery")
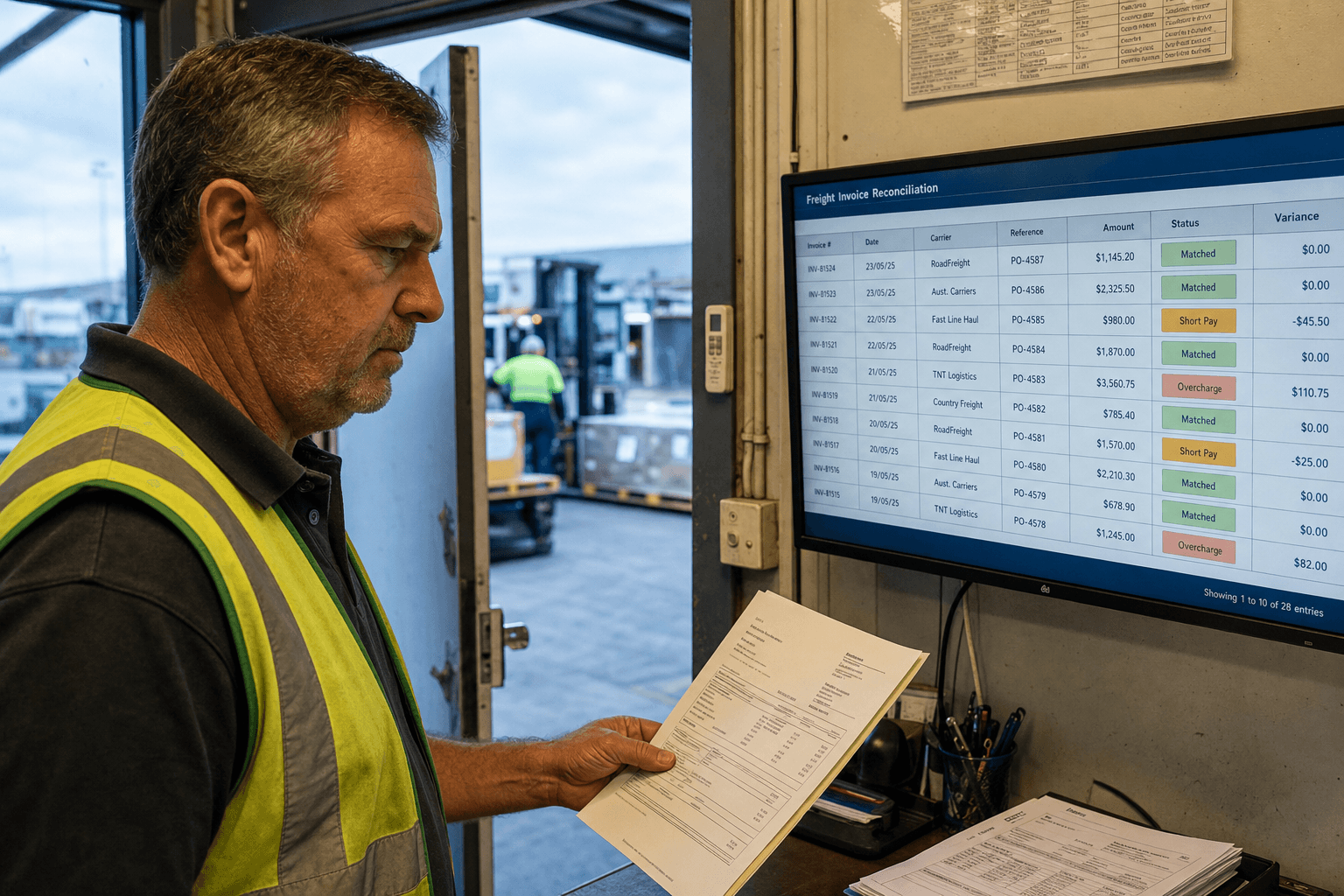
Freight Invoices
Freight invoice reconciliation is a well-known cost centre in logistics. Carrier invoices frequently contain charges that don't match agreed rates — fuel levies, tail-lift charges, re-delivery fees — and catching them manually requires line-by-line comparison.
Document intelligence can:
- Extract line-item charges from carrier invoices regardless of format
- Compare extracted charges against contracted rates in your TMS or rate table
- Flag discrepancies automatically for human review rather than requiring full manual audit
- Process invoices from multiple carriers with different formats using a single trained model
Customs and Import/Export Documentation
For freight forwarders and importers, customs documentation is both high-volume and high-stakes. Australian Border Force customs entries, commercial invoices, packing lists, and certificates of origin all contain structured data that currently requires manual entry into customs management systems.
Document intelligence applied here can:
- Extract HS codes, country of origin, declared values, and goods descriptions
- Pre-populate customs entries for broker review rather than requiring full manual data entry
- Cross-check declared values against commercial invoices to catch inconsistencies before lodgement
- Maintain a structured audit trail for ABF compliance purposes
Australian Regulatory Context
Any document intelligence solution deployed in Australian logistics must account for the following regulatory requirements:
Chain of Responsibility (COR) — HVNL. The Heavy Vehicle National Law places obligations on all parties in the supply chain, not just drivers. Consignment notes and load records are key evidence in COR compliance. Document intelligence must preserve audit trails and support records that can be produced in the event of an enforcement investigation.
Australian Border Force customs requirements. ABF requires that import and export documentation be accurate, complete, and retained for five years. Automated extraction must be validated against these requirements, and human-in-the-loop review is essential for high-risk or high-value shipments.
Biosecurity Act 2015. Certain commodities require phytosanitary certificates, import permits, and other biosecurity documents. Document intelligence can support extraction and validation of these documents, but compliance sign-off should remain with a qualified biosecurity officer.
Privacy Act 1988 (and upcoming reforms). Logistics documents frequently contain personal information — consignee names, delivery addresses, signatures. Any document processing system must comply with the Australian Privacy Principles (APPs) regarding collection, storage, and use of personal data.
Record retention. Under the Corporations Act 2001 and ATO requirements, financial records including freight invoices must generally be retained for seven years. Document intelligence systems must support compliant archiving, not just processing.
Integration with Existing TMS and WMS
One of the most common concerns we hear from operations managers is: "Will it work with our existing systems?" It's a fair question. Most mid-market operators are running legacy TMS or WMS platforms that are five to ten years old, with limited API capability.
The good news is that document intelligence doesn't require replacing your core systems. Well-designed implementations connect via:
API integration. Where your TMS has an API (even a basic REST API), extracted document data can be pushed directly into the system in structured format. Many legacy systems have APIs that aren't actively used — they just haven't been connected to anything.
Database-level integration. Where APIs aren't available, direct database writes or scheduled data file drops (CSV, XML, EDI) can bridge the gap. This is less elegant but pragmatic for older platforms.
Email and shared drive ingestion. Many operators receive documents via email or store them on shared drives. Document intelligence can monitor these inputs, process incoming files automatically, and output structured data without changing how documents arrive.
Human-in-the-loop review queues. For documents where confidence scores fall below a defined threshold, the system routes them to a human reviewer rather than processing automatically. This is how you handle edge cases without breaking the workflow.
The key principle: the integration architecture should fit around how your business actually operates, not require you to change your document handling processes to fit the software.
If you're assessing your current tech stack and readiness for integration, our AI Readiness Assessment is designed to map exactly this — what you have, where the gaps are, and what a realistic integration path looks like.
What to Expect in Terms of ROI
Note: The following framework is based on typical process analysis observations. We don't publish specific ROI figures because they vary significantly by operator size, document volume, and current process maturity. Any ROI estimate should be built on your actual data.
The ROI case for document intelligence typically rests on three levers:
1. Labour cost reduction. Manual document processing — keying BOL data, reconciling PODs, auditing invoices — is measurable in FTE hours. The starting point for any ROI calculation is quantifying how many hours per week your team spends on these tasks, at what fully loaded cost.
2. Error and exception reduction. Manually keyed data has error rates. Errors in logistics documentation cause real costs: re-deliveries, invoice disputes, customs delays, compliance findings. These costs are often dispersed across departments and hard to see as a single line item, but they accumulate.
3. Cycle time improvement. Faster document processing means faster invoicing, faster payment cycles, and faster response to customer queries. For 3PLs billing on delivery confirmation, reducing POD processing lag directly accelerates cash flow.
| ROI Lever | How to Quantify | What to Measure |
|---|---|---|
| Labour reduction | Hours/week on manual processing × FTE cost | Time tracking or process mapping exercise |
| Error reduction | Current error rate × cost per error event | Invoice disputes, re-delivery costs, compliance findings |
| Cycle time | Current document-to-action lag × volume | Days from POD receipt to invoice, from BOL receipt to TMS entry |
| Compliance risk | Current audit findings × remediation cost | Past COR, ABF, or ATO findings |
A realistic assessment for a mid-market operator processing several thousand documents per month should produce a payback period estimate grounded in your actual numbers — not a vendor's generic benchmark.
How Document Intelligence Supports Emissions Reporting
This is a connection that isn't immediately obvious but is increasingly relevant. Scope 3 emissions calculations for logistics operations require freight movement data — distances, load factors, vehicle types, fuel consumption. Much of this data currently lives in BOLs, consignment notes, and carrier invoices.
Document intelligence that extracts and structures this data as a by-product of normal processing provides a foundation for automated emissions calculation, rather than requiring a separate manual data collection exercise.
For operators preparing for AASB S2 compliance obligations, building document intelligence capabilities now creates dual value: operational efficiency today, and a structured data foundation for emissions reporting as obligations come into effect. If emissions reporting is on your radar, explore how our emissions reporting service connects to document data infrastructure.
Implementation: What a Realistic Timeline Looks Like
Document intelligence projects vary in scope, but a typical mid-market implementation follows a pattern:
Weeks 1–2: Discovery and document sampling. Collect representative samples of each document type. Assess current processing workflows and downstream system requirements. Identify priority document types by volume and pain level.
Weeks 3–6: Model training and integration build. Train extraction models on your specific document formats. Build integration connectors to target systems. Define validation rules and confidence thresholds. Set up human review queue for exceptions.
Weeks 7–8: Parallel run and testing. Run automated processing alongside existing manual process. Compare outputs. Tune models based on real document variation. Validate integration data quality.
Weeks 9–10: Go-live and stabilisation. Transition to automated processing for in-scope document types. Monitor exception rates. Refine as new document formats appear.
This is a 10–12 week timeline for a focused initial scope. It's not a multi-year transformation project.
Common Questions from Operations Teams
Will it handle our document formats? Our suppliers all send different layouts.
Yes — this is the core value of AI-based document intelligence over template-based OCR. Models trained on your document population learn to extract the right fields regardless of layout. Variation is expected, and modern models handle it well. Edge cases go to the human review queue.
What happens when the AI gets it wrong?
The system assigns a confidence score to each extraction. Documents below a defined confidence threshold are routed for human review before processing. This means errors don't propagate automatically — they get caught. The goal is to eliminate the high-volume, straightforward cases from the manual queue, not to remove humans from the process entirely.
Do we need to change how we receive documents?
Not necessarily. Most implementations work with existing document intake channels — email, shared drives, scanning stations, or mobile capture from drivers. The processing layer sits behind your existing intake, not in front of it.
How does this connect to our document-intelligence roadmap?
For operators who haven't yet mapped out what a document automation roadmap looks like for their specific tech stack and document types, our document intelligence service page outlines how we approach scoping and delivery.
Getting Started
If your team is spending meaningful time on manual document processing — BOL entry, POD chasing, invoice reconciliation, customs data prep — the ROI case for document intelligence is worth quantifying with your actual numbers.
The right starting point isn't buying software. It's understanding which documents create the most pain, what your current processing costs actually are, and what integration into your existing systems would require. That's exactly what our AI Readiness Assessment covers.
If you're ready to have that conversation, get in touch. We work with mid-market Australian logistics operators and we'll tell you honestly whether document intelligence makes sense for your operation — and what a realistic scope and timeline looks like.
For more practical guides on AI in Australian logistics operations, visit our insights.
Zero Footprint
The Zero Footprint team — AI modernisation for Australian logistics.


